Using Python LangChain and LLMs to audit Smart Contracts - Chainlink Blockmagic Hackathon
In May 2024, fresh off competing and winning a decent prize in the EthGlobal London Hackathon, I was on my hackathon bug; and with some small bit of convincing from my EthGlobal hackathon teammates, I decided to join them to take part in the Chainlink Blockmagic Hackathon.
The Idea
This hackathon was once again focused on the integration of blockchain technology to create some sort of innovative project. Though not particulary specific on potential topics that could be explored. One of my teammates suggested that we could build and AI powered smart contract auditor. Due to the immutable nature of blockchain transactions, there is a big risk of bugs in smart contract code resulting in very real physical losses for individuals and organizations. A small bug in transaction logic could present a very large vulnerability that bad actors can easily use to completely drain a crypto wallet. Furtheremore, with the relative lack of expertise in the field, access to competent smart contract auditors can be expensive and prohibative to smaller organizations or individuals. This is why the idea of an AI powered smart contract auditor was a potentially game-changing one. With the advance of LLMs in recent years, it had become inceasingly viable for an LLM to be given a chunk of text or some sort of information and be able to extract and interpret the data in such a way that useful insights can be gleaned. Putting all this together, the idea of the Defi Builder Smart Contract Auditor!

The innovation in our tool, exluding the obvious AI detection, would be that we would create a process through which real smart contract auditors would be able to view the AI suggestions given to other users' smart contracts and verify if these suggestions and vulnerability detections were accurate or not. For this effort, smart contract auditors would be rewarded and the AI would subsequently learn how to more accurately validate smart contracts.
So, the workflow for a use of the auditor might look like the following: User writes a smart contract -> They Use a GUI to submit their contract to the auditor -> The auditor analyses their contract and detects vulnerabilites -> Vulnerabilites as well as solutions are delivered back to the user This was the general flow we worked towards. The auditor would read code, and give back a report of Critical, High, Medium and Low vulnerabilities
For an auditor, the flow might look like this Is provided by a list of AI smart contract suggestions -> Using their experience they validate or correct the AI's suggestion -> They are given ranking and rewards for their contribution
Implementation Details
With all the functionality we planned to pack into the system, the architecture of the system would not be straightforward. However there are a few key components that would need to be built to facilitate the project. Namely: 1. AI Auditor Pipeline 2. Reward mechanics for human auditors 3. Frontend and GUI
A full architecture diagram is shown below. We can see the distinct flows for developers, who aim to have their smart contracts reviewed (and are rewarded for contributing their smart contract to DeFi builder), auditors (who are rewarded for validating the AI contract suggestions), normal users, who can make use of smart contracts in the DeFi builder database.

AI Auditing Pipeline
A major component of the project, the auditing pipeline would receive smart contracts, analyse the content of the contracts and somehow need to generate some sort of report for vulnerabilities detected in the contract itself. Furthermore, any "suggestions" that it made could then be reviewed and fed back to the model to be used in the future. Therefore some sort of feedback system needed to be created. In literature, and in the real world, there are systems like this that have been created that allow AI models to be always online and continuously trained with new data and feedback. TikTok actually published a really interesting whitepaper on this, where they presented an architecture and training method that would take real-time feedback from their app (i.e. users skipping videos, interacting, etc) and feed that back to train a subset of model parameters on their live recommendation model which would then be integrated into the real model. By cycling through training a subset of parameters, eventually, the whole model could be tweaked without going offline. Though initially, the idea was to recreate this sort of architecture, there was a difficulty in being able to host a model and train it with enough data for it to be effective in this way for the hackathon. Therefore, an alternative approach had to be considered.
Data Collection
The first step of the process for us was to get a solid set of data for our model to work with. To accomplish this, I made use of this awesome site: solidit.xyz , which compiles and lists a number of smart contract vulnerabilities. Unfortunately however, the site did not offer an easy API that could be interacted with to get the required vulnerability entries, therefore I created a simple webscraper in python that would log into the site, and scrape the required vulnerabilities. Some things I had to consider in our webscraper, because there is a significant amount of logging in and scrolling that needed to be done, I make use of the very useful selenium library in Python. Using this libray, a quick webscraper that logs into the site
if __name__ == '__main__':
parsers = {
"Sherlock": SherlockParser,
"Cyfrin": CyfrinParser,
"ConsenSys": ConsenSysParser,
"Pashov Audit Group": PashovParser,
"Trust Security": CyfrinParser,
}
url = 'https://solodit.xyz/'
options = webdriver.ChromeOptions()
options.add_argument('--headless=new')
browser = webdriver.Chrome(options=options)
SOURCE = "Trust Security"
FILESOURCE = SOURCE.replace(' ', '_')
linkfile = Path(utils.DATADIR, 'links', f'{FILESOURCE}_vulnerability_links.txt')
datafile = Path(utils.DATADIR, f'{FILESOURCE}_vulnerabilities_formatted2.txt')
browser.get(url)
login(browser)
then finds a link to all the vulnerabilites from a particular source type:
if not os.path.exists(linkfile):
search_by_source(browser, SOURCE)
sleep(5)
vulnerability_links = get_vulnerability_links(browser, backoff=2)
with open(linkfile, 'w') as f:
f.write('\n'.join(vulnerability_links))
Then goes through each vulnerability found, and parses it, extracting a JSON representation of the vulnerability which is saved:
for link in vulnerability_links:
try:
vulnerability = read_vulnerability(link, browser, parsers[SOURCE])
except Exception as e:
logger.error("Error reading vulnerability: %s", e)
vulnerability = DummyParser({"error": f'Error reading vulnerability {e}'})
with open(datafile, 'a', encoding='utf-8') as f:
f.write('\n')
f.write(link)
f.write('-'*50)
f.write('\n')
f.write('----Start JSON----\n')
f.write(json.dumps(
{key:vulnerability.__dict__[key] for key in vulnerability.__dict__
if key not in ['raw_html', 'soup', 'text']},
indent=4
))
f.write('\n----End JSON----')
f.write('\n')
For each source type, I created a custom parser class, which would be able to parse the relevant fields (as each sourcetype seemed to call things slightly differently), and generate congruent JSONs even though the sources themselves were not congruent. For reference, a SourceParser base class was created, which had methods for parsing code, text, etc.:
class SourceParser:
def __init__(self, html) -> None:
self.raw_html = html
self.soup = BeautifulSoup(self.raw_html, 'html.parser')
self.code = self.parse_code()
self.text = self.parse_text()
def parse_code(self):
return [code.text for code in self.soup.find_all('pre')]
def parse_text(self):
return '\n'.join([text.text for text in self.soup.find_all('p')])
def __str__(self) -> str:
return str(
{key:self.__dict__[key] for key in self.__dict__ if key not in [
'raw_html', 'soup'
]}
)
Then for each subsequent sourcetype with a differing format, I would create a child class which would inherit and add to, or override the super class methods. For example:
class SherlockParser(SourceParser):
def __init__(self, html) -> None:
super().__init__(html)
self.vulnerability_detail, self.vulnerability_code \
= self.parse_vulnerability_detail(
omit_code=bool(self.code)
)
self.summary = self.parse_summary()
self.imapct = self.parse_impact()
def parse_code(self):
"""Omitted code"""
return super().parse_code()
def parse_summary(self):
"""Omitted code"""
return text.lstrip('\n')
def parse_impact(self):
"""Omitted code"""
return text.lstrip('\n')
def parse_vulnerability_detail(self, omit_code=True):
"""Omitted code"""
return vulnerabilites
def parse(self, details_soup: BeautifulSoup):
code = details_soup.find('pre').text
text = details_soup.find('p').text
return code, text
I now had a solid base of vulnerabilities that I could use to train our our AI model. An example of our collected JSON vulnerabilities is as follows:
https://solodit.xyz/issues/lack-of-origin-check-on-rpc-requests-fixed-consensys-none-tezoro-snap-markdown
--------------------------------------------------
----Start JSON----
{
"code": [
"export const onRpcRequest: OnRpcRequestHandler = async ({ request }) => {\n switch (request.method) {\n case 'requestAccounts': {\n const data = await ethereum.request({\n method: 'eth\\_requestAccounts',\n\n",
"case 'getToken': {\n const state = await snap.request({\n\n",
"case 'saveToken': {\n const result = await snap.request({\n\n"
],
"Resolution": [
"Addressed by tezoroproject/metamask-snap#41"
],
"Description": [
"The Snap does not validate the origin of RPC requests, allowing any arbitrary dApp to connect to the Snap and initiate arbitrary RPC requests. Specifically, any dApp can access the privileged getToken and deleteToken RPC endpoints. Consequently, a malicious dApp could potentially extract a user\u2019s Tezoro token from the Snap and impersonate the user in interactions with the Tezoro API. Depending on the permissions associated with this token, the implications could be critical."
],
"Example": [
"packages/snap/src/index.ts:L14-L18",
"packages/snap/src/index.ts:L64-L65",
"packages/snap/src/index.ts:L34-L35"
],
"Recommendation": [
"Validate the origin of all incoming RPC requests. Specifically, restrict access to the RPC endpoints to only the Tezoro management dApp. Additionally, consider removing any endpoints that are not essential for the Snap\u2019s functionality. For example, the getToken endpoint for extracting the API token might be unnecessary and could be removed to enhance security."
]
}
----End JSON----
https://solodit.xyz/issues/getpriceofassetquotedinusd-might-return-flawed-asset-prices-fixed-consensys-none-tezoro-snap-markdown
--------------------------------------------------
----Start JSON----
{
"code": [
"if (assetName.startsWith('W')) {\n // Assume this is a wrapped token\n assetName = assetName.slice(1); // remove W\n}\ntry {\n\n",
"const response = await fetch(\n `https://api.binance.com/api/v3/ticker/price?symbol=${assetName.toUpperCase()}USDT`,\n);\nconst json = await response.json();\n\n"
],
"Resolution": [
"Addressed by tezoroproject/metamask-snap#42"
],
"Description": [
"First, the function getPriceOfAssetQuotedInUSD() operates under the assumption that stablecoins\u2014specifically \u2018USDT\u2019, \u2018USDC\u2019, \u2018DAI\u2019, \u2018USDP\u2019, and \u2018TUSD\u2019\u2014always maintain a 1:1 price ratio with the USD. Although this is generally expected to be the case, there have been instances where some stablecoins failed to uphold their peg to the USD. In such scenarios, this assumption no longer holds true, resulting in the return of inaccurate balances. Furthermore, it\u2019s important to note that the prices returned by this function are quoted in USDT, despite the function\u2019s name suggesting that prices are returned in USD. This could lead to discrepancies if \u2018USDT\u2019 diverges from its fiat counterpart.",
"Second, The function getPriceOfAssetQuotedInUSD() assumes that every token name that starts with \u2018W\u2019 is a wrapped token. Thus, the initial \u2018W\u2019 is removed from the token name before fetching the prices from Binance API. As a result, the subsequent API request made to get the price of the unwrapped token could potentially fail or return an incorrect price, if the token name starts with a \u2018W\u2019 but the token is not a wrapped token. For instance, the \u201cWOO\u201d token is present in the list of tokens supported by the Snap. In that case, the price API will error as it will try to fetch the price of theOOUSDT pair instead of WOOUSDT.",
"Finally, relying on an hardcoded external APIs is sub-optimal. Indeed, it may be that the API may fail, start returning incorrect data, or simply become outdated and stop working."
],
"Example": [
"packages/snap/src/external/get-price-of-asset-quoted-in-usd.ts:L15-L19",
"packages/snap/src/external/get-price-of-asset-quoted-in-usd.ts:L20-L23"
],
"Recommendation": [
"To mitigate this issue, one should avoid making assumptions about token names. Instead, one would ideally fetch token metadata from a trusted source to determine whether a token is wrapped or not, hardcode this information in the token-list, or directly fetch the price of the wrapped token.",
"Moreover, instead of hardcoding the price API, we would recommend setting up a custom API Gateway which provides a layer of abstraction between the Snap and the external APIs it uses. This would provide flexibility and allow quickly swapping for other external APIs in case they stop behaving properly."
]
}
----End JSON----
We have the link to the document, the vulnerability, as well as some markers I put in to parse the data effectively later on.
VectorDBs
A small but very important aspect of the whole AI pipeline is serving the data to an LLM effectively when its needed. I will not go into detail now, but unfortunately, it is very evident that normal data querying will not allow us to truly compare any bits of code in vulnerabilites in a meaningful enough way to allow the LLM/AI model to make connection between new code it sees and code in which we have identified an labelled the vulnerabilites. This is because with traditional database query methods, we tend to search for exact matches or patterns, however, in our case, any trained AI model needs to understand the meaning of a particular piece of code/vulnerability to make use of it to find vulnerabilites in new code we present it. This problem is solved by vector embeddings and Vector Databases.
Let's start with vector embeddings. Essentially, they allow us to map our code snippets into an n-dimensional vector space. How this mapping is done is non-trivial and in many cases, a seperately trained AI model is used to complete this task, however, in the end, we are left with a set of vectors, where if we calculate the similarity of these vectors, using standard linear alebraic similarity metrics (cosine similarity, l1/l2/l0 distances, etc) we can effectively match code snippets that are similar, without them actually being the same set of characters. We essentially match their meaning.
A vector database then, is a database that effectively allows us to store these vectors and query them effectively and quickly. The exact implementation surely depends on the databse being used, but in most cases, data is stored as an artifact, so in a no-SQL fashion. Once your data is stored, you generate an index for your data so that given a new vector embedding, similar embeddings are easily extracted from the database. Essentially the index created generates hashes to index the data in such a way in that when similar query vectors are presented to the database, they are guaranteed to generate hashes that point directly to the nearest neighbour vectors that already exist in the database. The following article goes into a bit more detail on how all this might work Vector Databases. For our project, I made use of Atlas DB from MongoDB to accomplish this.
We can see in the code below, where we have functions that both initialize our Vectorstore, as well as add documents to the vector store. When documents are added, their embeddings are automatically calculated before being added to the DB:
def initialize_mongo_vectorstore(
docs:Document,
database: str,
collection: str,
mongoclient: MongoClient,
embeddings_model:str
):
mongoclient = MongoClient(utils.ATLAS_DB_URI)
embeddings = OpenAIEmbeddings(
model=embeddings_model,
openai_api_key=os.environ.get('OPENAI_API_KEY')
)
db_name = database
collectionName = collection
collection = mongoclient[db_name][collectionName]
vector_store = MongoDBAtlasVectorSearch.from_documents(
docs,
embedding=embeddings,
collection=collection,
)
return vector_store
def add_documents(docs: list[Document], vectorstore: VectorStore):
if not isinstance(docs[0], list):
try:
docs = [make_document(entry=e) for e in docs]
except IndexError:
logger.error("Unsupported format, raw documents should be tuple of\
code and vulnerability detail e.g. (code, detail)")
return vectorstore.add_documents(
documents=docs,
)
Furthermore, the following notebook (very data scientist I know) shows the whole process of the Vector DB being initialized: Init Atlas DB
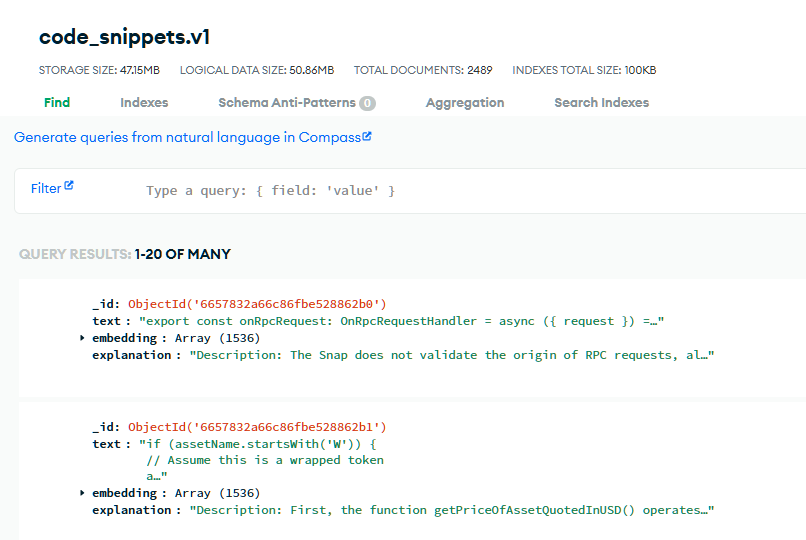
Generating Suggestions
Because we want to forego training our own model, we would have to find an alternative, luckily for us, there is an alternative. We can make use of RAGs or Retrieval Augmented Generation. In simple terms, this allows us to pass some sort of context to our AI model, which it can then use to give us a richer answer. For example, when you talk to ChatGPT, if you want something to be formatted in a particular way, you may give it some sort of example formatting, and when this prompt is sent to ChatGPT's model backend, it will be sent as some sort of context, which will be used to augment the generated prompt, in this case to fit in the formatting you provided. In our case, we want to somehow pass through information about relevant vulnerabilities to our LLM, along with our smart contract, so that when the LLM reads the smart contract, it can more easily identify problems we are looking for without actually being trained to specifically look for these problems. To enable this, I used LangChain in Python, which allowed me to create richer prompts with a technique called templating, which would then allow us to send structured queries to our LLM. In code, this looked something like this:
def create_function_prompt(user_code:str):
token_limit = 4096
encoding = tiktoken.get_encoding("cl100k_base")
system_prompt = SystemMessage("""
You are a blockchain smart contract auditor.
You help users understand if their smart contracts have vulnerabilites or not.
Given your own knowledge and context information, you will identify if a given function of code has vulnerabilites.
Be specific in you analysis and reference the user's code when explaining why the code is vulnerable.
You will need to identify start and end line number for the vulnerable user code as well as give a description of why the code is vulnerable.
Please provide a list of discovered vulnerabilites.
""")
user_start = (
"Analyze vulnerabilites in the smart contract code using the context below and your own knowledge.\n\n"+
"Context:\n"
)
user_end = (
"Please analyze the following smart contract code for vulnerabilites: \n"
)
prompt = (
system_prompt +
HumanMessage(content=user_start) +
"{context}" +
HumanMessage(content=user_end) +
"{user_code}"
)
Where we are creating a SystemMessage, where we tell our LLM its role, then we create our actual prompt, where we add our context, which is explained below, and other generated parameters. The context in our case, are similar vulnerabilities that we have in our database. To find these, we take our user_code which is the smart contract (we will explain below how I "massaged" this a bit to actually get relevant matches), and to a nearest neighbour search in a vector DB I created out of the code snippets I collected earlier (the vulnerabilities). Then the top X nearest neighbours are added to our prompt as a guide to the LLM, so it knows what it is looking for.
tokens_consumed = len(encoding.encode(
prompt.format(context='', user_code=user_code)
))
context_tokens_available = token_limit - tokens_consumed
context = object_similarity_search(
user_code,
db_name="code_snippets",
collection_name='v1'
)
contexts = ""
for i in range(len(context)):
formatted = context[i][0].page_content + context[i][0].metadata['explanation']
context_tokens = len(encoding.encode(formatted))
if (context_tokens_available) >= context_tokens:
contexts += formatted + "\n\n"
context_tokens_available -= context_tokens + 2
return prompt.format(context=contexts, user_code=user_code)
The rest of the function is just handling encoding and other trivial things. The nearest neighbour search happens in the object_similarity_search function. Where we calculate the embeddings for our code snippet, and do a nearest neighbour search in our vector DB of code snippets:
def object_similarity_search(
search_object,
k=5,
model="text-embedding-3-small",
db_name=os.environ.get("ATLAS_DB_DBNAME"),
collection_name = os.environ.get("ATLAS_DB_COLLECTION_NAME")
):
mongoclient = MongoClient(ATLAS_DB_URI)
embeddings = OpenAIEmbeddings(
model=model,
openai_api_type=os.environ.get('OPENAI_API_KEY')
)
db_name=db_name
collection_name=collection_name
collection = mongoclient[db_name][collection_name]
vector_search=MongoDBAtlasVectorSearch(
collection=collection,
embedding=embeddings
)
results = vector_search.similarity_search_with_relevance_scores(
search_object,
k=k
)
return results
One thing to note is that to generate vulnerabilites, we split our smart contract by functions and then put each function through our LLM. This is because our code snippets in our vector database had a smaller form factor, per function, and so the best way to get embeddings from our smart contract that would actually be similar to our collected code snippets would be to do our search per function. This is done by our utils.py/split_code_by_function function:
def split_code_by_function(code):
snippets = []
parentheses = []
opened = False
curr_function = ''
opposite = {
'}': '{',
']': '[',
')': '('
}
for char in code:
if char in '{([':
if char == '{':
opened = True
parentheses.append(char)
elif char in '}])':
if parentheses:
if opposite[char] == parentheses[-1]:
parentheses.pop()
curr_function += char
if opened:
if not parentheses:
opened = False
snippets.append(curr_function)
curr_function = ''
snippets.append(curr_function)
return snippets
Putting all these concepts together, we first use our LLM, giving a prompt and context to help us identify exactly where in our smart contract functions we have a vulnerability, we then go back to our vector DB and find out how closely these discovered vulnerable user functions match existing vulnerabilites in our database to generate a confidence score on our discovery. Finally, we feed these discovered vulnerabilities back through our LLM model to generate remediation actions. Eventually this results in an AuditReport object which organizes and compiles all the discovered vulnerabilites into the categories of Critical, High, Medium and Low levels and provides remediation actions for all of them. Once again using LangChain we ensure the format of this report by using a structured output, where we can ensure our answers are in a certain programtically friendly format. Everything is put together in our generate_function_audit function, which is exposed to our frontend using a simple REST API built in FastAPI.
## Query model
### We want to query the vector DB for similarity, then we will prompt the LLM
### to detect vulnerabilities, then we will query to suggest recommendations
@app.post('/audit_function')
async def audit_function(_function:Query) -> FunctionAuditReportOut:
try:
function_audit = generate_function_audit(_function.function_code)
return function_audit
except ConnectionFailure as e:
raise HTTPException(
status_code=503,
detail=f"Connection Error: {e}"
)
except (BulkWriteError, OperationFailure) as e:
raise HTTPException(
status_code=500,
detail=f"There was an error adding code examples: {e}"
)
except Exception as e:
raise HTTPException(
status_code=500,
detail=str(e)
)
def generate_function_audit(user_function) -> FunctionAuditReport:
# Split contract by functions; Generate vulnerabilites for each function
vulnerabilites = []
func_vuln = discover_function_vulnerabilites(user_function=user_function)
scores = object_similarity_search(
user_function,
db_name="code_snippets",
collection_name="v1"
)
scores = [score[1] for score in scores]
# Do something with the score
certainty_score = (sum(scores)/len(scores))*100
certainty_score = certainty_score if certainty_score < 100 else 100
for vuln in func_vuln.vulnerabilites:
vuln_recommendation = generate_recommendations(
user_function=user_function,
vulnerability_detail=vuln.detail+"Severity:"+vuln.severity.value
)
vulnerabilites.append(VulnerabilityAuditReport(
start_line=vuln.start_line,
end_line=vuln.end_line,
detail=vuln.detail,
severity=vuln.severity,
title=vuln.title,
recommendation=vuln_recommendation.recommendation,
certainty_score=certainty_score
))
return FunctionAuditReport(
function_code=user_function,
vulnerabilities=vulnerabilites
)
After running calling our generate_function_audit function, our LLM will return a response like this:
vulnerabilites=[Vulnerability(start_line=0, end_line=0, detail="The function does not validate the length of the 'signature' parameter, which could lead to potential vulnerabilities such as buffer
overflow or memory corruption if an excessively long signature is provided.", severity=<Severity.medium: 'medium'>, title='Missing Length Validation for Signature Parameter')]
You can see that we have information on the starting and ending lines of our captured vulnerability, some details, as well as the severity of the vulnerability. Unfotunately, and output of the final AuditReport object had not been captured.
Continuous Learning
Though not a major part of the hackathon project demo itself, re-training the model in order to make it better and better was a big part of the idea behind the project. In our RAG setup, this manifested itself as a system where recommendations reviewed and discovered by real world AI auditors could be sent back to our AI backend, where they would be formatted, embeddings generated, and then added back into our vector databse. This is evident from the /add_code_example endpoint, where we complete this process:
@app.post("/add_code_examples", response_model=DocumentsAdded)
async def add_code_examples(snippets:CodeExampleList) -> JSONResponse:
docs = []
for snippet in snippets.code_examples:
docs.append(create_document(
code=snippet.code,
detail=snippet.detail,
impact=snippet.impact,
likelihood=snippet.likelihood,
severity=snippet.severity,
recommendation=snippet.recommendation
))
dbname=os.environ.get('ATLAS_DB_DBNAME')
collection=snippets.collection or os.environ.get('ATLAS_DB_COLLECTION_NAME')
try:
add_documents(
docs=docs,
vectorstore=MongoDBAtlasVectorSearch().from_connection_string(
connection_string=ATLAS_DB_URI,
namespace=f"{dbname}.{collection}"
)
)
# Search VectorDB for
return {
"status": 201,
"detail": "Code examples were successfully added to vulnerbaility store"
}
except ConnectionFailure as e:
raise HTTPException(
status_code=503,
detail=f"Connection Error: {e}"
)
except (BulkWriteError, OperationFailure) as e:
raise HTTPException(
status_code=500,
detail=f"There was an error adding code examples: {e}"
)
You can see, that we generate a document from the recieved recommendation, and then generate an embedding and add it back to our vector DB
Conclusion
All in all, the above article should have explained how I was able to create an effective AI audit pipeline for our smart contract auditor hackathon entry. The full entry (along with a very cool demo video) can be seen here: DeFi Builder Smart Contract Auditor and the GitHub repo with all the source code can be found here: GitHub Repo